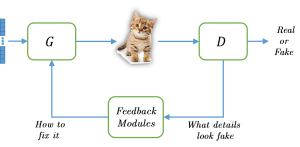
The adversarial feedback loop: Classic GAN is composed of two components: the generator (G) and the discriminator (D). In this setting, the information flow is done purely by back-propagation, during training. We propose adding a third component – the feedback module that transmits the discriminatory spatial information to the generator in a feedback manner at inference time.
Thanks to their remarkable generative capabilities, GANs have gained great popularity, and are used abundantly in state-of-the-art methods and applications. In a GAN based model, a discriminator is trained to learn the real data distribution. To date, it has been used only for training purposes, where it’s utilized to train the generator to provide real-looking outputs. In this paper we propose a novel method that makes an explicit use of the discriminator in test-time, in a feedback manner in order to improve the generator results. To the best of our knowledge it is the first time a discriminator is involved in test-time. We claim that the discriminator holds significant information on the real data distribution, that could be useful for test-time as well, a potential that has not been explored before. The approach we propose does not alter the conventional training stage. At test-time, however, it transfers the output from the generator into the discriminator, and uses feedback modules (convolutional blocks) to translate the features of the discriminator layers into corrections to the features of the generator layers, which are used eventually to get a better generator result. Our method can contribute to both conditional and unconditional GANs. As demonstrated by our experiments, it can improve the results of state-of-the-art networks for super-resolution, and image generation.
The full paper can be found here. Supplementary
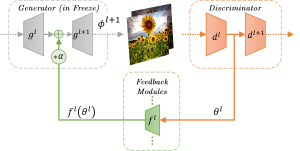
The feedback framework: The proposed feedback module passes information from the discriminator to the generator thus “learning” how to correct the generated image in order to make it more real in terms of the discriminator score.

Faces generated with AFL show significantly fewer artifacts, making clear the advantage of using AFL.
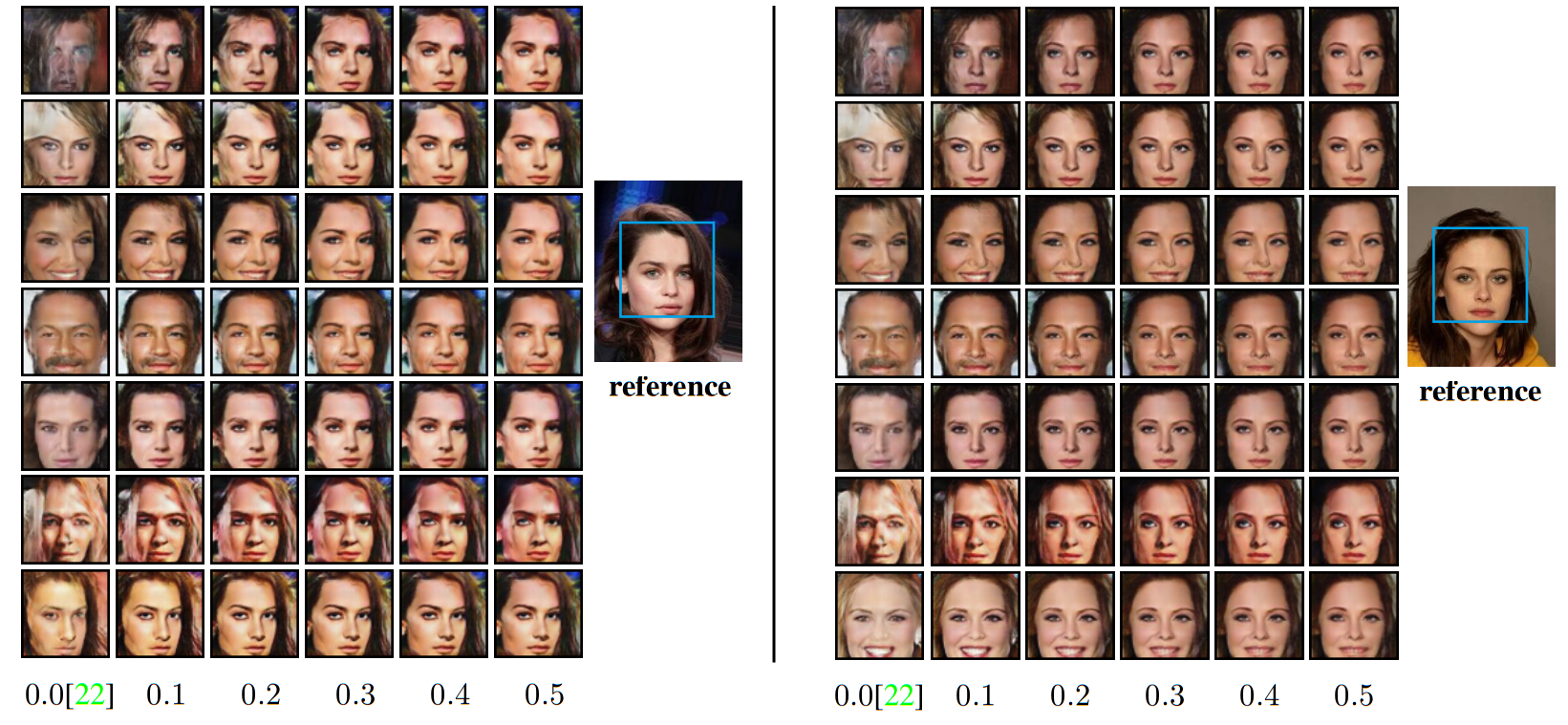
Generation with reference: Results of using feedback-switching-pipeline. The feedback modules make the generated image similar to the reference one, and with fewer artifacts. First column is DCGAN baseline.


Our feedback loop removes artifacts and sharpen the image
Code of the experiments described in our paper is available Here
